ほぼテク読者の皆様、いつも大変ありがとうございます!
我妻裕太です。
本日もよろしくお願いいたします。GPTに関する連続投稿約90日目です!
本日はChatGPTの有効活用方法の検討です!
少し時間が空いてしまいましたが「文章の中の大事な単語を拾い出す」実験をChatGPTで試してみようシリーズです。テーマも前回から継続して論文です!
研究者ネットワークの分析とは
科学技術研究の世界では、一つの研究が進展するために、多くの研究者が手を組み、共同研究を行っています。論文の著者リストを見れば、それぞれの研究がどのような研究者ネットワークにより支えられているのかが垣間見えます。
このような情報を整理し、視覚化することによって、一つ一つの研究がどのようなコラボレーションの結果であるのか、また、どの研究者が特定の研究分野で中心的な役割を果たしているのかを理解することができます。これが研究者ネットワークの分析というものです。
研究者ネットワークの分析のよくある課題

しかし、この研究者ネットワークの分析を行うためには、まず各論文から著者名を抽出し、それを適切な形式に整形するという作業が必要となります。この作業は意外と手間がかかり、特に大量の論文を扱う場合にはその負担は増大します。それぞれの論文から著者名をコピーペーストし、それをプログラムで処理できる形式に変換するのは、繰り返しの手作業によるエラーが発生しやすく、また時間もかかる作業です。
ChatGPTによる課題解決

ここで登場するのがChatGPTです。ChatGPTは、人間が書いたテキストを理解し、必要な情報を抽出・整形する能力を持っています。論文のテキストから著者名を抽出し、それをPythonプログラムで使用できる形式に整形する作業も、ChatGPTによって自動化することが可能です。
それではさっそく試してみましょう!
今回の実験ルールは以下の通りです。
【実験ルール】
- サンプルの論文データから著者とその論文情報を特定のフォーマットに変換できるか実験します。
- GPT-3.5で実験する。
- プロンプトは以下で実行します。
【プロンプト】
論文情報から著者とその論文を以下のフォーマットイメージのとおりの辞書として定義してください。
## フォーマットイメージ
papers = {
“Evolution and Applications of Deep Learning”: [“Taro Yamada”, “Jiro Sato”, “Saburo Suzuki”],
“Current Status and Prospects of Quantum Computing”: [“Jiro Sato”, “Saburo Suzuki”, “Shiro Tanaka”],
“Artificial Intelligence and Ethics”: [“Saburo Suzuki”, “Shiro Tanaka”, “Rokuro Takahashi”, “Hachiro Nakamura”]
}
## 論文データ
(ここに論文データを貼り付ける)
以下が与えられた論文情報から生成した辞書です。
papers = {
“Evolution and Applications of Deep Learning”: [“Taro Yamada”, “Jiro Sato”, “Saburo Suzuki”],
“Current Status and Prospects of Quantum Computing”: [“Jiro Sato”, “Saburo Suzuki”, “Shiro Tanaka”],
“Integration of AI and Big Data”: [“Taro Yamada”, “Shiro Tanaka”],
“New Frontiers in Natural Language Processing”: [“Jiro Sato”, “Goro Watanabe”],
“Advances in Molecular Biology”: [“Saburo Suzuki”, “Rokuro Takahashi”],
“The Future of Robotics Technology”: [“Shiro Tanaka”, “Goro Watanabe”, “Rokuro Takahashi”],
“Novel Approaches in Environmental Science”: [“Taro Yamada”, “Shichiro Ito”],
“Applications of AI in Psychology”: [“Jiro Sato”, “Saburo Suzuki”, “Hachiro Nakamura”],
“Emerging Trends in Data Science”: [“Taro Yamada”, “Jiro Sato”, “Hachiro Nakamura”, “Shichiro Ito”],
“Artificial Intelligence and Ethics”: [“Saburo Suzuki”, “Shiro Tanaka”, “Rokuro Takahashi”, “Hachiro Nakamura”]
}
この辞書では、各論文のタイトルをキーとし、その論文に関連する著者の名前をリストとして値としています。複数の論文が同じ著者を共有している場合には、その著者の名前が複数の論文に含まれるようになっています。また、新しい論文が追加される際には、同じフォーマットに従って情報を追加していくことができます。
おぉ、おぉーーーー、早い、本当毎回思うこと、とても早いです!
ちゃんと整形してくれています!これを無料のGPT-3.5でできてしまうのは凄いな。
今まではプログラムを起動したり、なければコーディングしたり、場合によっては手作業で作成してなくてはいけないデータが一瞬で手に入る!こんなに素晴らしい世の中はないのではないでしょうか。言い過ぎか(笑)
で、これをPythonのNetworkXで可視化するとこのようなイメージになります。
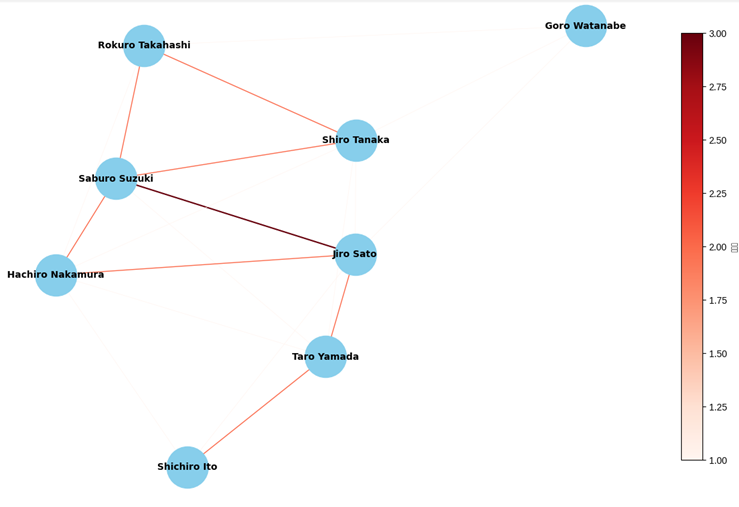
おぉーーーー、可視化されている。ちゃんとネットワーク図になっている。
これで色々な研究者同士のつながりが可視化されて色々と分析できそうですね。
ソースコードは以下のものでGoogleColabで実行したものです。
何かの参考になれば幸いです!
import networkx as nximport matplotlib.pyplot as plt# 論文情報から著者とその論文を辞書として定義papers = {“Evolution and Applications of Deep Learning”: [“Taro Yamada”, “Jiro Sato”, “Saburo Suzuki”],“Current Status and Prospects of Quantum Computing”: [“Jiro Sato”, “Saburo Suzuki”, “Shiro Tanaka”],“Artificial Intelligence and Ethics”: [“Saburo Suzuki”, “Shiro Tanaka”, “Rokuro Takahashi”, “Hachiro Nakamura”],“Integration of AI and Big Data”: [“Taro Yamada”, “Shiro Tanaka”],“New Frontiers in Natural Language Processing”: [“Jiro Sato”, “Goro Watanabe”],“Advances in Molecular Biology”: [“Saburo Suzuki”, “Rokuro Takahashi”],“The Future of Robotics Technology”: [“Shiro Tanaka”, “Goro Watanabe”, “Rokuro Takahashi”],“Novel Approaches in Environmental Science”: [“Taro Yamada”, “Shichiro Ito”],“Applications of AI in Psychology”: [“Jiro Sato”, “Saburo Suzuki”, “Hachiro Nakamura”],“Emerging Trends in Data Science”: [“Taro Yamada”, “Jiro Sato”, “Hachiro Nakamura”, “Shichiro Ito”],“Artificial Intelligence and Ethics”: [“Saburo Suzuki”, “Shiro Tanaka”, “Rokuro Takahashi”, “Hachiro Nakamura”]}
# 著者のネットワークを作成G = nx.Graph()# 著者をノードとして追加for paper, authors in papers.items():G.add_nodes_from(authors)# 共著関係をエッジとして追加for paper, authors in papers.items():for i in range(len(authors)):for j in range(i + 1, len(authors)):if G.has_edge(authors[i], authors[j]):# 既にエッジが存在する場合はエッジの重みを増やす(共著数を表す)G[authors[i]][authors[j]][‘weight’] += 1else:G.add_edge(authors[i], authors[j], weight=1)# グラフを描画plt.figure(figsize=(12, 8))pos = nx.spring_layout(G, seed=42) # 描画のためのノードの位置を設定# エッジの重み(共著数)に応じてエッジの幅と色を設定edge_width = [0.5 * G[u][v][‘weight’] for u, v in G.edges()]edge_color = [G[u][v][‘weight’] for u, v in G.edges()]nx.draw(G, pos, with_labels=True, node_size=2000, node_color=”skyblue”, font_size=10, font_weight=’bold’,width=edge_width, edge_cmap=plt.cm.Reds, edge_color=edge_color)# カラーバーを追加sm = plt.cm.ScalarMappable(cmap=plt.cm.Reds, norm=plt.Normalize(vmin=min(edge_color), vmax=max(edge_color)))sm._A = []plt.colorbar(sm, label=”共著数”, shrink=0.8)plt.title(“著者のネットワーク(共著数によるエッジの重み付け)”, fontsize=14)plt.axis(‘off’)plt.show()
まとめ
っということでいかがでしたでしょうか。
今日もまた面白かったですね。単純だけど大変な作業は世の中にはたくさんあるはず!
そういった作業を少しでも減らして人はもっと創造的な仕事にシフトできるとより良い世の中になるのではないでしょうか。
本日の記事がみなさまの業務効率化のヒントになれば幸いです。
今回も最後までお読みいただき、ありがとうございました。
それでは、また次回のほぼテクでお会いしましょう!
SRA東北の我妻裕太でした。
さようなら!

株式会社SRA東北ビジネス・ディベロップメント
チーフ・ディレクター 我妻裕太
バックナンバー
ほぼテク 7月21日GPTのライバルになるか?ついに登場IBM WatsonからLLMが登場!その名もwatsonx!
ほぼテク 7月20日GPTと創る新しいビジネス体験の世界へ!Bing Chat EnterpriseとMicrosoft 365 Copilotの進化!
ほぼテク 7月18日ChatGPTで「文章の中の大事な単語を拾いだす」テキストデータから宝を見つける究極のガイド?論文から引用解析編!
ほぼテク 7月14日ChatGPTで「文章の中の大事な単語を拾いだす」テキストデータから宝を見つける究極のガイド?論文から専門用語と概念抽出!
ほぼテク 7月13日ChatGPTで「文章の中の大事な単語を拾いだす」テキストデータから宝を見つける究極のガイド?論文メタデータ編!
ほぼテク 7月11日ChatGPTで「文章の中の大事な単語を拾いだす」テキストデータから宝を見つける究極のガイド?レシピ開発編!
ほぼテク 7月10日ChatGPTで「文章の中の大事な単語を拾いだす」テキストデータから宝を見つける究極のガイド?スケジュール管理編!
ほぼテク 7月7日AIで「文章の中の大事な単語を拾いだす」テキストデータから宝を見つける究極のガイド?マーケット調査編!
ほぼテク 7月6日ChatGPTで「文章の中の大事な単語を拾いだす」テキストデータから宝を見つける究極のガイド?契約書編!
ほぼテク 7月4日ChatGPTで「文章の中の大事な単語を拾いだす」テキストデータから宝を見つける究極のガイド?ニュース記事の分析編!
ほぼテク 7月3日ChatGPTで「文章の中の大事な単語を拾いだす」テキストデータから宝を見つける究極のガイド?カスタマーサービス編!
ほぼテク 6月30日ChatGPTと固有表現抽出!テキストデータから宝を見つける究極のガイド?SNSマーケティング編!
ほぼテク 6月29日ChatGPTと固有表現抽出!テキストデータから宝を見つける究極のガイド?
ほぼテク 6月27日GPT活用で時短!議事録作成の革新的な効率化テクニック②GPT、Bardで議事録作成!
ほぼテク 6月26日GPT活用で時短!議事録作成の革新的な効率化テクニック①GPTによる架空の議事録生成実験
ほぼテク 6月23日GPTはメールの緊急度はチェックできるのか実験をしました!
ほぼテク 6月22日GPTと自社データをシームレスに結びつける新サービス「Azure OpenAI Service On Your Data」公開プレビュー!を徹底解説!
ほぼテク 6月20日メールをチェックするのはあなたとChatGPT!
ほぼテク 6月19日ChatGPTのリアル活用事例を参考にシステム開発の目線で仕組みを考えてみました!
ほぼテク 6月16日GPT-4!テクノロジーの進化と新たな可能性
ほぼテク 6月15日ChatGPTがさらにパワーアップ!新モデルと機能のリリース情報?
ほぼテク 6月13日大好きChatGPT!全知全能の神様ではない、その真実に迫る?
ほぼテク 6月12日ChatGPTの言語理解力を革新する「大規模言語モデル」を徹底解説?
ほぼテク 6月9日AIを活用した業務効率化!ChatGPTでのタスク管理と優先順位付け?
ほぼテク 6月8日AIとメールの融合?ChatGPTを活用したメール作成術!
ほぼテク 6月6日AIと英語学習の融合?ChatGPTの有効活用法!
ほぼテク 6月5日ChatGPTで金融業でのAI活用?クライアント情報の間違いを探し出す
ほぼテク 6月2日AIの進化とレシピ生成の競争:ChatGPT「GPT-3.5」対「GPT-4」対Google Bard
ほぼテク 6月1日新3大AI!ChatGPT or Google Bard比較パート⑥(一番上手そうなレシピを生成してくれるのはどれか?Google Bard編)
ほぼテク 5月30日新3大AI!ChatGPT or Google Bard比較パート⑤(一番上手そうなレシピを生成してくれるのはどれか?GPT-4編)
5月29日新3大AI!ChatGPT or Google Bard比較パート④(一番上手そうなレシピを生成してくれるのはどれか?GPT-3.5編)
5月26日新3大AI!ChatGPT or Google Bard比較パート③(だれが回答を出す際の音速の貴公子か?)
5月25日ChatGPT or Google Bard比較パート②(生成AIに最新情報は取得できるか)
5月22日(ChatGPTを自社Webサイトに組み込むには? )
5月19日(ChatGPTを自社システム・自社サービスに組み込むには? )
5月15日(ChatGPTと過ごした3日間?AI・人工知能EXPO出展報告、ChatGPT対応ソリューション多数ございます!)
5月2日(スケール則(scaling law):極めて重要な法則)


